
A CSS refactor lands. A data-testid gets renamed. Forty Playwright tests go red before anyone has coffee.
None of them found a bug. They found a selector that moved.
If you run a small QA team, you already know this tax. Most of your “test maintenance” time is not testing. It is chasing the DOM around the page like a technician with a flashlight in a rewired server room.
Vision-based E2E is one answer to that problem. Magnitude is one implementation worth understanding, not because it is the future of QA, but because its architecture teaches a useful budget trick: split expensive reasoning from cheap perception. That split is the part worth stealing, whether or not you ever adopt the tool.
The maintenance trap
Traditional browser tests are precise. They are also fragile in a very specific way.
When frontend refactors, your suite does not fail on user-visible breakage alone. It fails on structural drift:
- renamed classes and attributes;
- moved nodes in the DOM tree;
- swapped
data-testidconventions; - layout changes that leave the UI functionally identical.
Your tests were written against markup. The product changed pixels and structure. The suite stayed loyal to the old coordinates.
That is why small teams burn so many hours on locator archaeology. You are not validating behavior. You are re-mapping a moving blueprint.
What Magnitude actually is (read the label)
Before you reorganize a release pipeline, look at what you are buying.
If you land on Magnitude’s GitHub repo today, the headline reads “The best coding agent for open models,” not a test framework. The README opens with “Magnitude is built from the ground up around open models. It matches the performance of Claude Code at 5x lower token prices” and never mentions testing, Playwright, selectors, or vision once. The testing framework still exists. It lives in the docs, which describe Magnitude as “an open source AI browser automation framework” and still document test cases, test runners, and web-testing pages. But it has been demoted from the project’s flagship identity to one capability under a broader browser-automation umbrella. This is the team’s second pivot: they started as a coding agent, pivoted to E2E testing around April 2025, and have since swung the repo headline back toward open-model coding.
For a QA engineer, that context matters:
- License: Apache-2.0, not MIT (Copyright 2025 Magnitude AI Inc.).
- Maturity: pre-1.0 alpha; the latest observed CLI tag is
@magnitudedev/cli@0.0.1-alpha.14, andmainhas seen active development recently. Treat it as a pilot, not infrastructure. - Docs drift: the testing docs look less maintained than the code. The planner-model recommendation still names Claude Sonnet 3.7 in places, even though the repo moves faster. Verify every config field against current docs before you copy snippets from any article, including this one.4. Identity risk: the testing framework is not the headline product anymore.
So this is not “the open-source Playwright killer the repo sells.” It is a vision-based automation experiment with a genuinely interesting cost architecture, living inside a project with a wandering center of gravity. The parts QA cares about still work as documented. With that framing straight, the architecture is worth understanding.
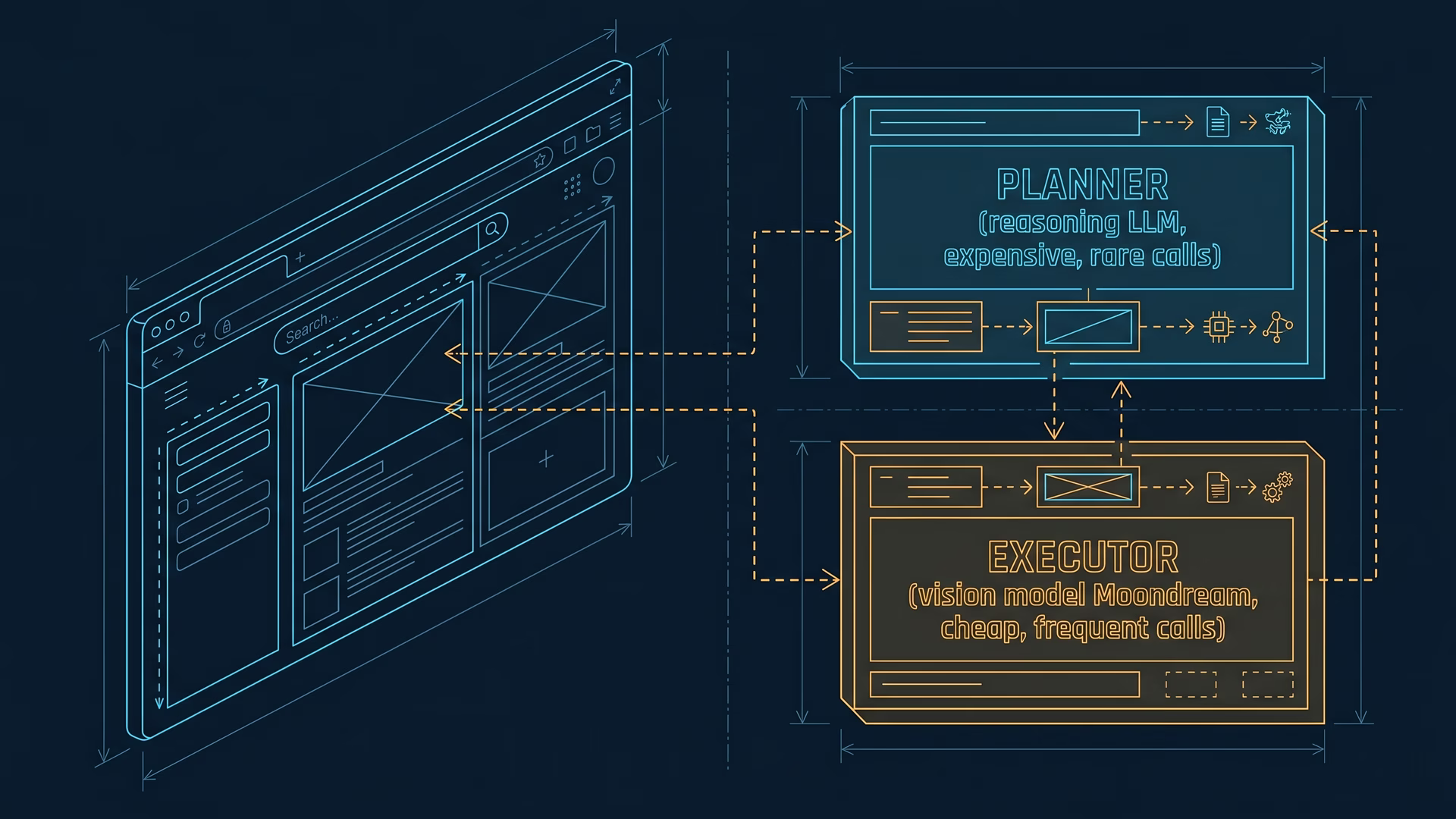
Blueprint: planner and executor
The useful idea is architectural, and it reads like an engineering schematic.
Magnitude splits work between two models with different jobs:
- Planner (reasoning layer): a strong general-purpose LLM reads intent (“log in, add the cheapest item, check out”) and produces a step sequence. Docs recommend a capable model here, such as Gemini 2.5 Pro or Claude Sonnet 3.7, configured in
magnitude.config.ts. Called rarely. Expensive per call, but low frequency. - Executor (grounding layer): a compact vision model looks at a screenshot and answers one question: “where do I click?” Magnitude uses Moondream, a small open-source VLM, for this path. Called constantly. Must stay cheap.
Planning is the expensive, reasoning-heavy part, and in a well-designed system you want to avoid redoing that work more often than necessary. Acting on the screen is the high-frequency part, and it runs on a model small enough to host yourself. Match model cost to call frequency.
| Layer | Playwright / Cypress | Magnitude |
|---|---|---|
| How it finds targets | CSS, XPath, data-testid | Vision model reads rendered pixels |
| What breaks a test | DOM structure changes | Meaningful visible UI changes |
| Where intelligence lives | Your locator code | Planner LLM + grounding VLM |
| Self-hostable core | Browser driver | Grounding model (Moondream) |
Think of it as two chips on one board:
- Chip A plans the route once.
- Chip B reads the screen every step.
You do not need a flagship model burning tokens on every click.
Why small teams can afford the experiment
The cost story holds up if you stay honest about what “cheap” means.
Where costs stay low
-
Moondream is open source and self-hostable, so high-frequency “look at the screen” calls do not have to hit a paid API.- Hosted Moondream tiers have advertised 5,000 free requests per day at the time of writing; verify the current quota before planning around it. For a small suite, that tier can cover pilot executor traffic.
-
The planner runs far less often than the executor.
-
The repo’s broader pitch still points at low-cost open models: “matches the performance of Claude Code at 5x lower token prices” plus starter credits with no card required. Where costs do not disappear
-
The planner is still a paid LLM call when it runs.
-
Self-hosting Moondream adds ops work: GPU/CPU, uptime, monitoring.
-
“Cheap” is relative to a fully hosted agent stack, not to a free CSS selector.
Plan caching: read the fine print
You may see Magnitude described as having “plan caching”: generate the plan once with an expensive model, then replay it cheaply forever. That exact named feature is not confirmed in current first-party docs. What the docs describe instead is “Memory and Prompt Caching”, which is related but not the same mechanism. Do not build a budget case on a marketing phrase. The durable lever is architectural: an expensive planner you call rarely, and a cheap, self-hostable executor you call constantly. If cost assumptions matter to your pilot, read the caching page in the docs and treat any third-party article (including this one) as secondary.
What a test looks like on paper
Treat the API as a moving target. Alpha software, drifting docs. The shape is stable even when field names are not.
Configure both models in magnitude.config.ts:
// magnitude.config.ts (illustrative; verify field names against current docs)
import { defineConfig } from "magnitude-test";
export default defineConfig({
// Reasoning model. Called rarely, so a strong (pricier) model is fine.
planner: {
provider: "google",
model: "gemini-2.5-pro",
},
// Grounding model. Called constantly, so keep it small and local.
grounding: {
provider: "moondream",
// self-hosted endpoint or hosted free tier
},
});The test reads like intent, not locator chains:
// example.mag.ts (illustrative)
test("guest can check out the cheapest item", async (agent) => {
await agent.act("add the cheapest item in the catalog to the cart");
await agent.act("go to checkout as a guest");
await agent.check("the order summary shows exactly one item");
});Notice the absence:
- no
page.locator('[data-testid="..."]'); - no selector waits;
- no CSS archaeology.
The planner turns language into steps. The grounding model finds pixels. When a designer reshuffles markup but the screen still reads like a checkout flow, the test has a fighting chance to survive.
That is the whole pitch in three lines. It is also where the tradeoffs begin.
Wins, limits, and where it fits
Walk in with both columns, not just the sales pitch.
Where vision-based intent tests win
-
Refactor resilience: DOM moves that redden selector suites may not touch intent-based tests if the UI still reads clearly to a human.
-
Maintenance language: “Check out as a guest” documents behavior better than a chain of brittle locators.
-
Cost at the hot path: a self-hostable executor keeps high-frequency perception off a token meter.
-
Local control: Apache-2.0, open grounding model, open-model-first project philosophy. Where they still lose (for now)
-
Determinism: a vision model choosing click targets wobbles in ways
#submit-btnnever will. -
Failure triage: “the AI clicked the wrong thing” is harder to debug than a missing element.
-
Ecosystem depth: Playwright and Cypress bring years of CI recipes, plugins, and community answers.
-
Product maturity: pre-1.0 alpha inside a repivoting repo is real operational risk.5. Ops overhead: cheap inference can still mean you operate a model.
For most teams, the practical approach is:
- keep Playwright or Cypress on deterministic, high-value core flows;
- pilot vision-based intent testing on brittle, layout-heavy journeys that eat maintenance time.
If your week is mostly selector repair, the same pain we mapped in playwright-api-logger, that is the use case worth a controlled experiment.
Should you try it? A one-week pilot
If you are a small QA team drowning in selector maintenance, Magnitude is worth a weekend pilot, specifically because the executor is small and self-hostable, which keeps the experiment cheap. Go in with eyes open: it is alpha, it is not the project’s flagship anymore, and “plan caching” is not a confirmed named feature you can budget on.
Do not migrate a suite on faith. Run a small, measured pilot instead.
1. Read the docs first
Open the current testing docs and confirm config fields, provider names, and caching behavior. Do not trust snippets from this article over the source. 2. Pick one expensive flow
Choose a journey that breaks often after UI refactors: checkout, onboarding wizard, settings with nested tabs. Port only that flow. One test file. One CI job. No big-bang rewrite.
3. Start on hosted Moondream
Use the free tier first. Stand up self-hosting only if the pilot proves value. 4. Measure for seven CI days
Track:
- pass rate vs. your Playwright baseline on the same flow;
- mean reruns per merge;
- time to diagnose failures;
- maintenance edits required after frontend changes;
- flakiness rate before you migrate anything that matters.
5. Decide with numbers, not narrative
If flakiness stays high or triage time grows, keep the architecture lesson and skip the migration.
The bet Magnitude makes, describe intent and let a model find the pixels, is a credible direction for resilient UI automation. Whether this particular alpha belongs in your pipeline is a question only a cheap, bounded pilot can answer.
References
- Magnitude GitHub repository — README, releases, license
- Magnitude documentation — testing pages, providers, caching