

How I dived into LangGraph and Langfuse through a single experiment — and what evaluation taught me about testing AI agents.
Project repo: https://github.com/AZANIR/lang_test
You can learn a tool from its docs. Or you can run an experiment with it and watch what breaks. I went with the second. I already had a small bot that drafted bug tickets — a plain n8n + Telegram flow, tidy nodes, all working. And that’s exactly why it nagged at me: it worked, but I couldn’t prove it was good, and I couldn’t tell whether a change made it better. As an AQA I’m used to having an answer to “are we sure it works?” Here, I didn’t.
So I set up an experiment: rebuild that same bot as a LangGraph agent, wrap it in Langfuse, and — most importantly — learn to measure it. What follows is the story of that experiment. Spoiler: the interesting part wasn’t how the agent writes tickets. It was how evaluation caught me lying three times — in my agent, in my “fix”, and in my metric.
The thesis, up front: for AI agents, eval is not a grade you hand the model at the end. It’s the instrument that tells you the truth about what your system — and your own assumptions — are actually doing.
The test subject: an agent that writes bug tickets
An experiment needs a subject — a task real enough to hurt, small enough to hold. Bug tickets are perfect. The idea: give the agent the minimum — a description and a screenshot — and have it analyze the image, ask me anything it’s missing, and assemble a complete QA ticket with the screenshot wired in.
Why not stay in n8n? Honestly, n8n is great. Visually fast, Telegram UX for free, prebuilt integrations. And here’s the surprise I found along the way: n8n’s AI nodes are themselves built on LangChain. So the question was never “n8n vs LangChain” — it was visual orchestration vs code orchestration: how much control do I actually need? And I needed it exactly where n8n started to creak: the interview loop (“ask until you have enough, then stop”), guaranteed ticket fields, and — most of all — the ability to test and version. That last one became the real point of the experiment.
Dive one: LangGraph
LangGraph models a process as an explicit state graph with first-class human-in-the-loop support. My interview mapped onto it perfectly:
flowchart TD
START --> ingest[ingest: parse input<br/>file/URL, image/video, base64]
ingest --> analyze[analyze: vision analysis of the screenshot]
analyze --> assess{assess: enough info?}
assess -- needs more --> interview[interview: interrupt(questions)<br/>pause for the human]
interview --> assess
assess -- enough / limit --> draft[draft: generate BugTicket]
draft --> write[write: folder + copy attachments + ticket.md]
write --> ENDThe whole “pause and ask” behaviour is two primitives:
# interview node — the graph literally falls asleep here and waits for a human
from langgraph.types import interrupt
def interview_node(state):
answers = interrupt({"questions": state["questions"]}) # <- execution pauses
merged = {**state.get("answers", {}), **(answers or {})}
return {"answers": merged, "interview_rounds": state["interview_rounds"] + 1}A front-end resumes the graph with Command(resume=answers); a checkpointer keyed by thread_id
holds the conversation between turns. Compared to the visual flow, three things became mine:
HITL as a language feature, structured output (with_structured_output(BugTicket) returns
validated Pydantic with automatic retries), and testability — it’s just Python.
I baked that last one into the architecture from the start: one brain, swappable front-ends.
flowchart LR
subgraph brain[LangGraph: one graph + checkpointer]
g[ingest → analyze → assess ↔ interview → draft → write]
end
cli[CLI] --> brain
tg[Telegram] --> brain
eval[Eval harness] --> brainA single helper, step_graph(), runs one step and reports either ("interview", questions) or
("done", final). The CLI wraps it in a loop, the Telegram bot drives it from chat events, the
eval harness drives it from a dataset. No graph node ever changed to add a front-end. Dive one
succeeded: the agent ran, the first ticket landed in output/. But that’s where the real story
begins.
”But is it any good?” Dive two: Langfuse
Here the tester in me had to grow up. You can’t assertEqual an LLM. The output differs every
run; “correct” is a spectrum, not a boolean. So I assembled an eval harness out of three
parts.
Observability. One callback turns every run into a Langfuse trace: the graph nodes and every LLM call, with tokens and latency, nested in one tree.
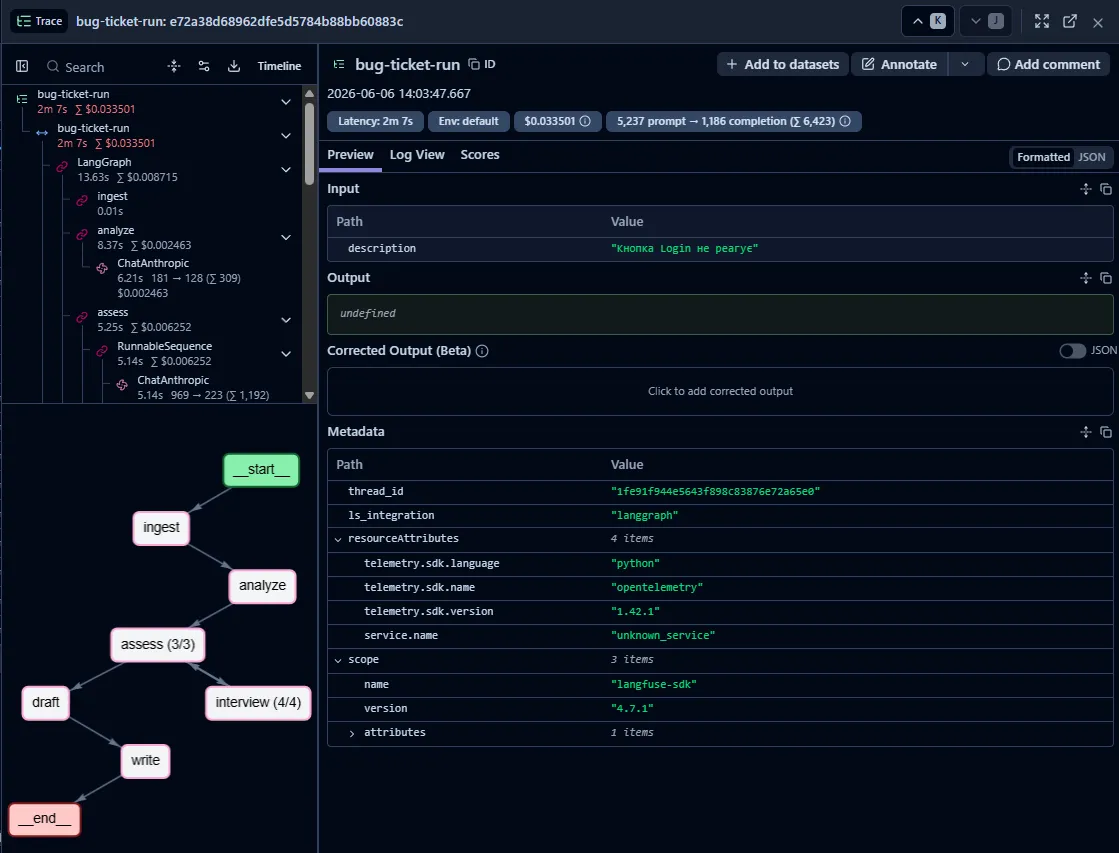
Figure 1 — One run as a trace: every node and model call, with tokens and latency.
LLM-as-judge. Four reference-free judges score each ticket 0–1 with a one-sentence rationale: completeness, faithfulness (no hallucination), reproducibility, interview_quality. A judge is just a structured call:
class JudgeVerdict(BaseModel):
score: float = Field(ge=0, le=1)
reasoning: str
def _make_evaluator(criterion):
def _evaluator(*, output, **_):
verdict = judge(criterion, _format_subject(output)) # one call, temperature=0
return Evaluation(name=criterion, value=verdict.score, comment=verdict.reasoning)
return _evaluatorA dataset + experiment runner. A handful of cases run through the agent autonomously via
run_experiment(...), and the judges score every output. Scores land back in Langfuse, side by
side, run over run. That word — autonomously — hid the first surprise, because an autonomous run
has no human to answer the interview. More on that in a moment.
Three surprises you can’t see by eye
This is the heart of the experiment. I would not have reached any of these conclusions by reading outputs. Each one is the eval doing its real job: telling me the truth.
Surprise 1: the bug can be in your metric, not your agent
The very first measured run was alarming:
| Criterion | Baseline |
|---|---|
| faithfulness | 0.47 |
| completeness | 0.65 |
| reproducibility | 0.51 |
| interview_quality | 0.65 |
Faithfulness at 0.47 reads as “the agent hallucinates half the time.” I almost started rewriting the prompt. Then I read the judge’s reasoning — and that habit saved me. It was flagging facts like “Chrome 120,” “Server error,” the test account — as invented. But they were real: the reporter had supplied them in the interview answers.
The bug wasn’t in the agent. It was in my measurement: I was passing the judge the questions the agent asked, but not the answers it received. The judge literally couldn’t see that the “hallucinated” facts had been provided. One payload fix later:
| Criterion | Baseline | After fix #1 |
|---|---|---|
| faithfulness | 0.47 | 0.91 |
Nothing about the agent changed. I had graded it on a test with half the answer key missing. Takeaway: when a metric screams, suspect the metric first. An eval you don’t audit is just a confident liar.
Surprise 2: “I improved the prompt” is a hypothesis, not a result
The same baseline surfaced a real agent flaw: the interview asked duplicate questions (“which environment?” twice, reworded). Easy, I thought — I’ll just tell the model not to repeat itself. I added a crisp instruction to the assess prompt and reran.
| Criterion | Baseline | After “fix” |
|---|---|---|
| interview_quality | 0.65 | 0.32 |
It got worse. The judge still found duplicates everywhere; the polite instruction simply didn’t bind. (A second measurement artifact hid here too — below.) Had I shipped on vibes, I’d have shipped a regression and called it an improvement.
So I replaced the wish with a guarantee: a deterministic code-level dedup that drops any
question overlapping an already-asked one (overlap coefficient on content tokens), plus running
assess at temperature=0. Code always runs; a prompt is a suggestion.
And the artifact: my dataset answered every question with the same block of facts, so most questions were effectively unanswered and the agent kept probing — which looked like bad interviewing. I replaced the blob with a simulated reporter: a small LLM that plays the user and answers each question from the case’s facts — or honestly says “haven’t checked.”
def _simulated_reporter(item):
facts = item["answers_text"]
sim = get_model(temperature=0)
system = ("You are the bug REPORTER. Answer ONLY from the facts you know. If they don't "
"cover the question, say 'Haven't checked / can't say.'\nFacts:\n" + facts)
def provider(questions):
return {q: sim.invoke([SystemMessage(system), HumanMessage(q)]).text for q in questions}
return providerWith the real fix and an honest test:
| Criterion | Baseline | Prompt “fix” | Code dedup + simulated reporter |
|---|---|---|---|
| faithfulness | 0.47 | 0.91 | 0.89 |
| completeness | 0.65 | 0.62 | 0.70 |
| reproducibility | 0.51 | 0.51 | 0.51 |
| interview_quality | 0.65 | 0.32 | 0.71 |
One case that had been riddled with duplicates scored 0.95 on interview quality and read like a human had asked the questions. Takeaway: “I improved the prompt” is a hypothesis. The number is the result.
Surprise 3: honesty costs you a metric
Now the judges gave real, product-level feedback. One sharp note: the agent invented a repro
step (“fill in the mandatory fields”) the reporter had never confirmed. So I grounded the draft:
state only confirmed facts; mark anything unknown as (not confirmed) rather than guessing.
| Criterion | Before grounding | After grounding |
|---|---|---|
| faithfulness | 0.893 | 0.947 ⬆️ |
| completeness | 0.703 | 0.683 |
| reproducibility | 0.513 | 0.433 ⬇️ |
| interview_quality | 0.707 | 0.720 |
Faithfulness went up — and reproducibility went down. My first instinct was “regression.” It wasn’t. The old reproducibility score had been inflated by hallucination: the agent wrote plausible, confident steps it had no basis for, and they looked reproducible. Now, when the input genuinely lacks detail, the ticket says so — and the metric reflects the real information gap.
That’s the lesson that actually changed me: faithfulness and reproducibility are in tension when the input is incomplete. Fabrication trades one for the other. The only honest way to lift both is to get more out of the reporter — better elicitation — not better guessing. A ticket that admits “(not confirmed)” beats one that confidently misleads an engineer. I kept the change.
This is why eval is a truth mechanism
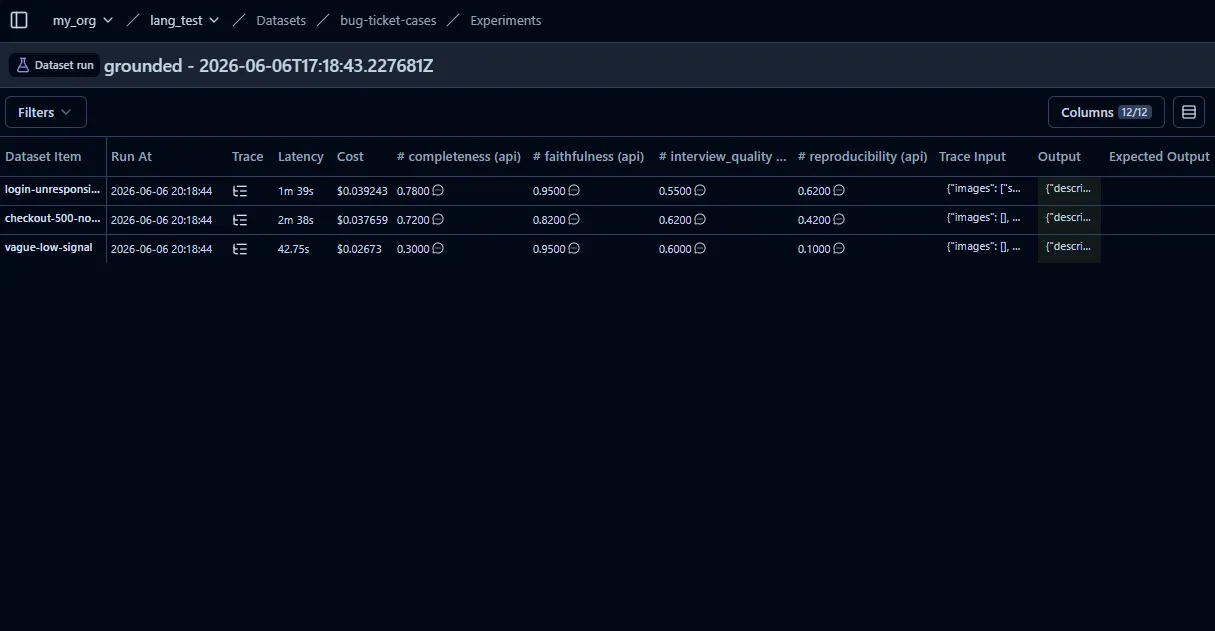
Figure 2 — Each fix is an experiment; the judges score it; the deltas are the verdict.
Every improvement had the same shape:
trace it → run the eval → read the judge's reasoning → form a hypothesis
→ change one thing → re-run the eval → keep it only if the number movedNone of the three surprises were visible by eye. They were visible because there was an instrument pointed at the system. That is the payoff of code orchestration I couldn’t get from a visual flow: not nicer code — an objective improvement loop. Which was, all along, my answer to the question that started the experiment.
Telegram: same brain, different voice
n8n’s one genuine advantage was the Telegram front-end, so I gave the LangGraph brain the same
voice. Because the interview is event-driven in chat (each message is a separate event), the bot
uses step_graph() plus a tiny per-chat marker; the checkpointer (keyed by chat ID) holds the
interview state. No graph node changed. I added one-line logging and watched a real run from
my phone:
🤖 Bot started (long-polling)
[chat …] 📥 photo ← screenshot received
[chat …] ❓ asked 4 question(s) ← vision → assess → interrupt, questions to chat
[chat …] 📥 text ← my answers
[chat …] ❓ asked 4 question(s) ← second round (MAX_INTERVIEW_ROUNDS = 2)
[chat …] 📥 text ← my answers
[chat …] ✅ ticket: output\…\ticket.md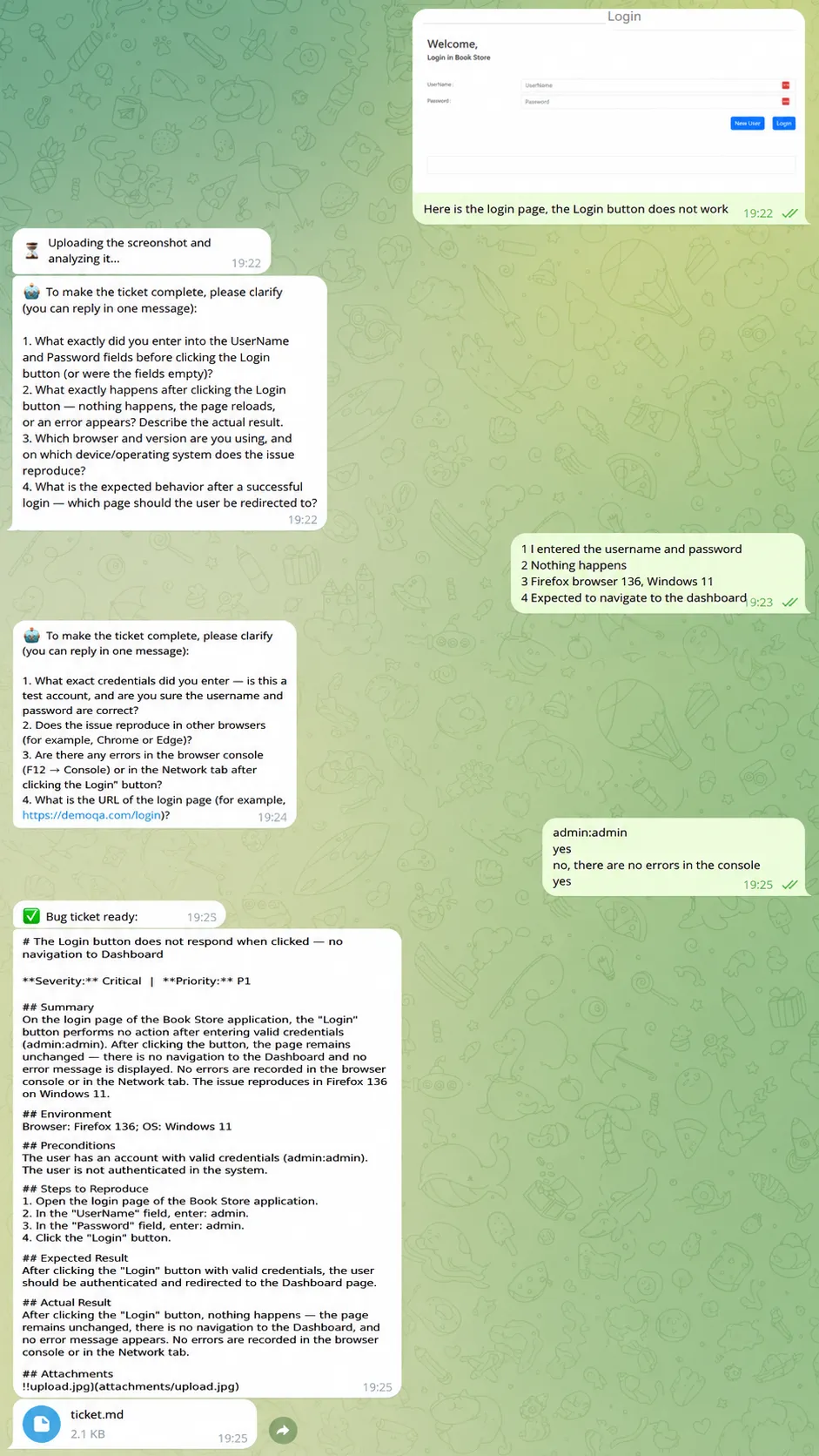
Figure 3 — The same interrupt/resume interview, now as a chat: in goes a screenshot, back comes a
ticket and a .md file.
What the experiment gave me
I started out to save myself some typing. I came out with a small but real shift in how I think about testing.
- Testing agents ≠ testing deterministic software. There’s no golden output. You test with judges, datasets, and distributions of scores — and you treat your judges and datasets as code that can be wrong too.
- The metric is part of the system under test. Two of my three biggest “agent problems” were measurement problems. Auditing the judge’s reasoning is now a habit, not an afterthought.
- “Better” is a number with a before and an after. No measured delta, no improvement claim. It’s just QA discipline applied to a fuzzier target.
- Honesty is a quality attribute. An agent that says “(not confirmed)” is more trustworthy than one that fills the gaps with confident fiction — and a good eval surfaces the difference instead of rewarding the fiction.
And the experiment turned out to be the best way to dive into LangGraph and Langfuse. Not “I read a chapter,” but “I ran a real task through them and earned real bruises.” A tool you’ve wrestled with in an experiment stays in your hands, not in your bookmarks.
Where I’d go next: the judges still flag semantic duplicate questions my lexical dedup misses (embeddings would catch those), and the real lever for reproducibility is an agent that pushes harder to elicit detail (HTTP status, console errors) instead of accepting “don’t know.” Both are now easy to justify — because I can measure whether they help.
If you want to try it yourself
The full code is on GitHub: https://github.com/AZANIR/lang_test
Stack: LangGraph (graph + interrupt/checkpointer), LangChain (init_chat_model,
with_structured_output, provider-agnostic), Langfuse 4.x (tracing, run_experiment,
LLM judges), pyTelegramBotAPI, Pydantic, Python 3.12. 36 tests, all artifacts in the project.
# CLI
python -m bug_ticket_agent.cli -d "Login button does nothing" --image samples/shot.png
# Eval (traces + judge scores land in Langfuse; --hosted unlocks Datasets → Runs)
python -m bug_ticket_agent.eval --hosted
# Telegram bot (needs TELEGRAM_BOT_TOKEN)
python -m bug_ticket_agent.telegram_botModels and keys live in .env (MODEL, JUDGE_MODEL, LANGFUSE_*, TELEGRAM_BOT_TOKEN);
swapping the LLM provider is a one-line change.
Every number in this article is taken verbatim from the project’s own run logs — which is, after all, the whole point.